SPIDAL Project¶
The goal for the SPIDAL project is to create software abstractions to help connect communities together with applications in different scientific fields, letting us collaborate and use other communities’ tools without having to understand all of their details. The project will integrate features of traditional high-performance computing, such as scientific libraries, communication and resource management middleware, with the rich set of capabilities found in the commercial Big Data ecosystem. The latter includes many important software systems, such as Hadoop, available from the Apache open source community.
At present one of our main goals is to establish a set of benchmarks for Big Data analysis in the spirit of the Berkeley Dwarfs and NIST 2013 Big Data Applications. Through the publication of several research papers in the past year, we have sought to collect applications and their feature and summarize key properties, followed by identifying and classifying requirements with comparison to already established attributes like those of NIST. Our work has culminated in the definition of around 50 essential features or ‘facets’ of Big Data that we call Ogres.
These Ogres are further divided into four distinct views: Problem Architecture View (AV), Execution View (EV); Data Source and Style View (DV), and Processing View (PV). The following table highlights the different views and their corresponding facets.
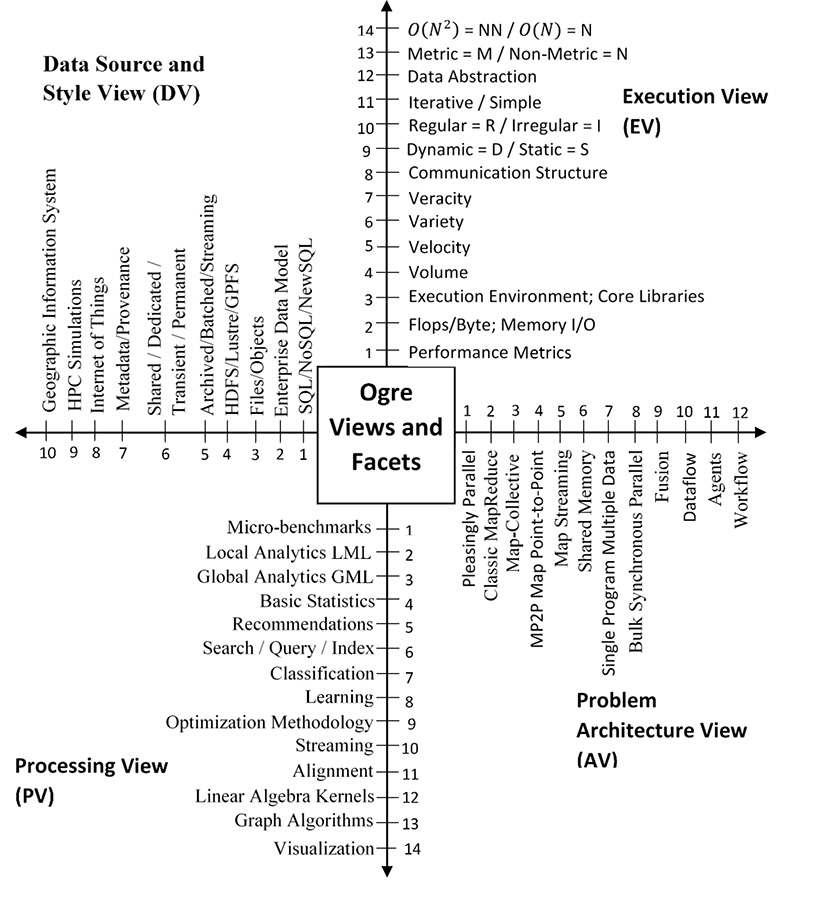
Spidal Dimensions
Contents: